24 September 2025
Paper
5 mins read

Post author

Rezza Moieni
Chief Technology OfficerIn this research post
Get this paper
Newsletter subscription
If you’re feeling like a sitting duck in this new age of AI, you are not alone! As artificial intelligence becomes more and more a part of our everyday lives, it is certainly easy to feel increasingly vulnerable. This is not just a vague anxiety, with our personal information constantly exposed, and with traditional data protection methods beginning to fail.
Why Anonymity is at Risk in the AI Era?
AI systems possess an extraordinary capability to transform what appears to be benign data into significant personal identifiers. Cutting-edge machine learning techniques can merge information from various sources to pinpoint individuals, challenging long-held beliefs regarding the effectiveness of de-identification. Even anonymized information from legal rulings or chatbot training can be susceptible to re-identification by advanced AI.
Our thorough analysis of 64 peer-reviewed studies uncovered concerning results: despite using conventional anonymization techniques, AI was able to achieve re-identification accuracy of up to 99.8% from data that was thought to be anonymous. In one striking example, Large Language Models (LLMs) successfully identified individuals from Swiss court rulings that had been professionally anonymised, simply by cross-referencing writing patterns with publicly available information.

The problem here isn’t just general data collection. It is about a fundamental mismatch between technology and legal safeguards. The European Data Protection Regulation (GDPR), for example, was written before technologies like generated learning and large language models came into the mainstream. Therefore, here is the critical gap in which our privacy is most vulnerable.
In our previous paper, we discussed why a Secure Diversity and Inclusion Survey is the Backbone of Trust and True Inclusion?In that research, we reviewed 30+ differrent regulations, compliances and frameworks around the world that could be applied on any data collections, especially in the area of humanity, people and social science.
The Regulatory Gap: Why GDPR Falls Short?
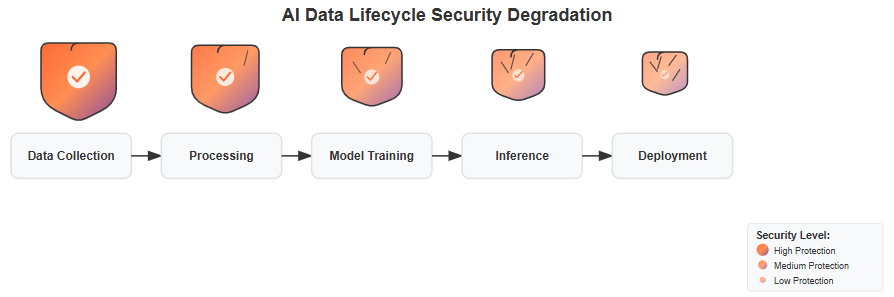
The GDPR’s protections are strong enough during the initial data collection, but they weaken significantly as data moves through the AI lifecycle. Our paper shows that during model inference and post-deployment, key articles in the GDPR often provide little to no coverage.
A significant issue we discover is that the GDPR’s definition of “personal data” is often too narrow. High-risk data categories such as learned embeddings (numerical representations of data) and synthetic corpora (artificially generated datasets) can fall outside the regulation’s scope. This allows companies to argue that once data is transformed, it is no longer legally protected. Additionally, the GDPR’s consent logic is often “stuck at the moment of collection,” failing to address how data is used in later stages like fine-tuning, which can amplify exposure.
A Path Towards Hope: Bridging the Gap
While the challenges here are significant, our paper also details a path toward restoring anonymity. A single solution is insufficient; effective anonymity requires a combination of new technology and updated regulations.
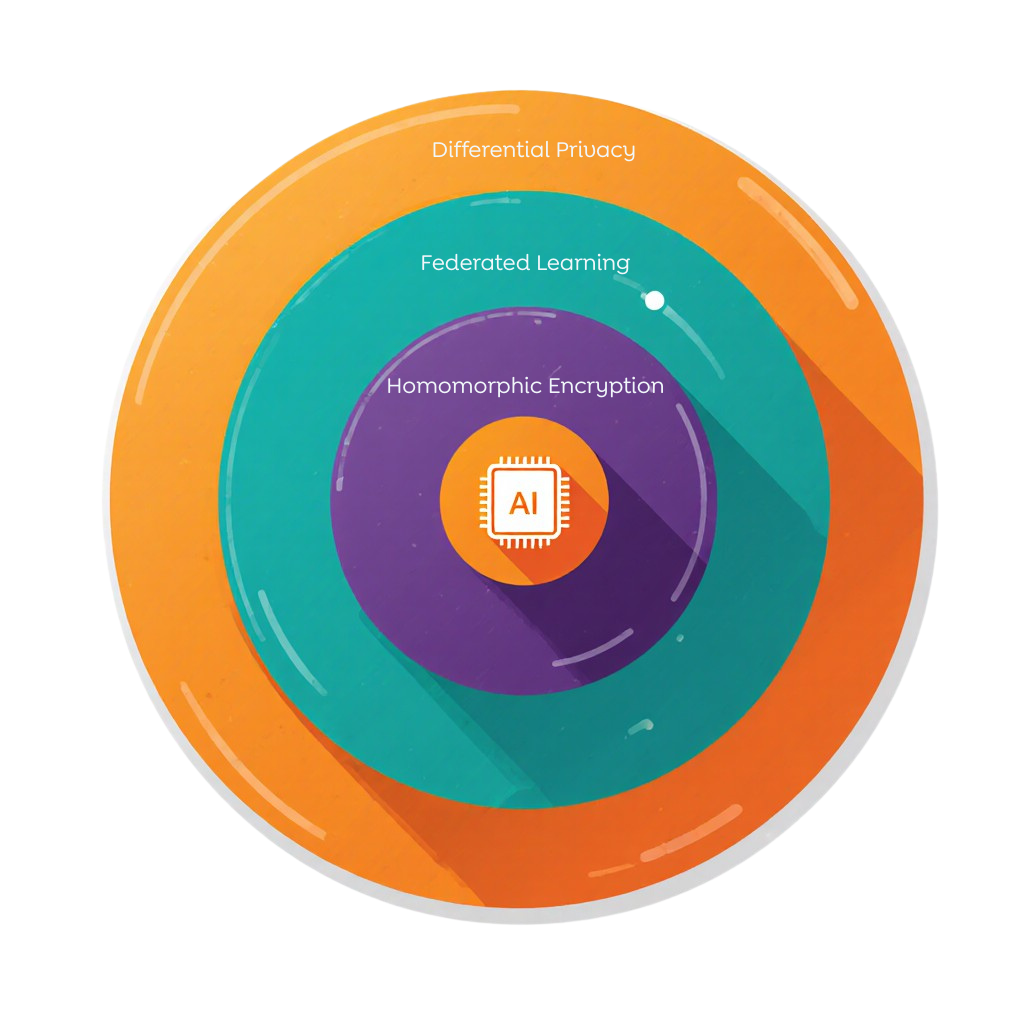
On the technical front, a layered approach using Privacy-Enhancing Technologies (PETs) has shown promising results. The most resilient configurations combine differential privacy (which adds noise to data), federated learning (which trains models on decentralized data), and homomorphic encryption (which allows computations on encrypted data)00. This hybrid approach can block sophisticated attacks while maintaining high accuracy.
On the regulatory front, our paper recommends:
- Following the data: Regulations must track data across its entire lifecycle, not just at the point of collection.
- Explicitly naming high-risk data: Formal guidance should explicitly name data categories like learned embeddings and synthetic corpora to remove ambiguity.
These changes would align legal protections with the modern realities of AI pipelines.
What´s next?
This post has only just scratched the surface of the complex relationship between AI and anonymity. To truly understand these challenges and the proposed solutions, we need to delve into the details. Such as…
- How exactly do techniques like model-inversion and prompt-leakage work, and what makes them so dangerous?
- What are the specific performance trade-offs—such as accuracy loss and computational cost—when using layered privacy-enhancing technologies?
- How do different types of data, from unstructured text to behavioural traces, require different anonymisation strategies?
- Beyond the GDPR, what other legal frameworks are being explored to regulate AI privacy, and what are their strengths and weaknesses?
To get a full picture and explore the research behind these findings, read the full paper: “Anonymity in the Age of AI” , written by Parisa Shojaei , Nabi Zameni and Rezza Moieni from Cultural Infusion